През изминалата година малко теми предизвикаха повече дискусии в света на данните, отколкото мрежите за данни. Въпросът е дали мрежите за данни са готови за най-доброто време.
Data Mesh
Да централизирате или разпределите управлението на данни? Този въпрос е на първо място, откакто миникомпютрите на отделите нахлуха в предприятието, последвани още по-подривно от персонални компютри и локални мрежи, минаващи през задната врата. И конвенционалната мъдрост се люлее напред-назад оттогава. Системи за работни групи или отдели, за да направят данните достъпни, след това консолидации на корпоративни бази данни, за да се отървете от цялото дублиране.
Помните ли кога езерото с данни трябваше да бъде крайното състояние? Точно като корпоративното хранилище за данни преди него, идеята, че всички данни могат да се събират на едно място, така че имаше само един източник на истина, до който всички сфери на живота в предприятието можеха да имат достъп нереалистично. Свързаността на интернет, привидно евтиното съхранение и безкрайната мащабируемост на облака, експлозията на данни от интелигентни устройства и IoT заплашва да претовари хранилищата и езерата от данни толкова трудно настройвам.
Езерни къщи с данни напоследък се появиха, за да донесат най-доброто от двата свята, докато мрежите за данни и интелигентните центрове за данни оптимизират компромисите между виртуализиране и репликиране на данни.Би било безсмислено да се твърди, че някоя от тези алтернативи предлага окончателния сребърен куршум.
Въведете Data Mesh
През изминалата година се появи нова теория, която признава безполезността на подходите отгоре надолу или монолитните подходи за управление на данни: мрежата от данни. Докато голяма част от светлината на прожекторите напоследък беше върху AI и машинното обучение, в света на данните има по-малко теми, които рисуване повече дискусия отколкото мрежа от данни. Просто погледнете данните от Google Trends за последните 90 дни: търсенията за Data Mesh далеч надхвърлят тези за Data Lakehouse.
Той е създаден от Жамак Дехгани, директор на следващата технологична инкубация в Thoughtworks Северна Америка, чрез обширен набор от произведения, започващи с въведение още през 2019 г, подробно описание на принципите и логическата архитектура в края на 2020 г, което скоро ще кулминира в книга (ако се интересувате, Данни за Starburst предлага кратък поглед). Мрежите с данни често са били в сравнение с тъканите за данни, но внимателното четене на работата на Dehghani разкрива, че това е повече за процес, отколкото за технология, както Джеймс Сера, ръководител на архитектурата в EY и преди това в Microsoft, правилно отбеляза в публикация в блог. Независимо от това, темата за мрежите от данни (които са разпределени изгледи на масива от данни) срещу. тъканите за данни (които прилагат по-централизирани подходи) заслужават своя собствена позиция, тъй като интересът и към двете беше доста подобен.
Просто казано, ако това е възможно, мрежата от данни е не технологичен стек или физическа архитектура. Data mesh е процес и архитектурен подход, който делегира отговорността за конкретни набори от данни на домейни или области на бизнесът, който има необходимата експертиза по предмета, за да знае какво трябва да представляват данните и как трябва да бъдат използвани.
Това има архитектурен аспект: вместо да се предполага, че данните ще се намират в езеро от данни, всеки „домейн“ ще отговаря за избора как да хоства и обслужва наборите от данни, които притежава.
Освен външното регулиране или политиката на корпоративно управление, домейните са причината, поради която се събират специфични набори от данни. Но дяволът е в детайлите, а те са много.
Така че мрежата от данни не се дефинира от хранилището на данни, езерото с данни или езерото с данни, където физически се намират данните. Нито се дефинира от обединяването на данни, интегрирането на данни, системата за заявки или инструментите за каталогизиране, които попълват и анотират тези хранилища на данни. Разбира се, това не е спряло доставчиците на технологии от измиване на мрежи за данни техните продукти. През следващата година е вероятно да видим доставчици на каталози, машини за заявки, канали за данни и управление да рисуват своите инструменти или платформи в светлината на мрежата от данни. Но тъй като виждате маркетинговите послания, не забравяйте, че мрежите от данни са свързани с процеса и начина, по който прилагате технология. Например, машината за обединени заявки е просто инструмент, който може да помогне на екип с внедряването, но сам по себе си не превръща внезапно масив от данни в мрежа от данни.
Основните стълбове
Data Mesh е сложна концепция, но най-добрият начин да започнете е като разберете принципите зад нея.
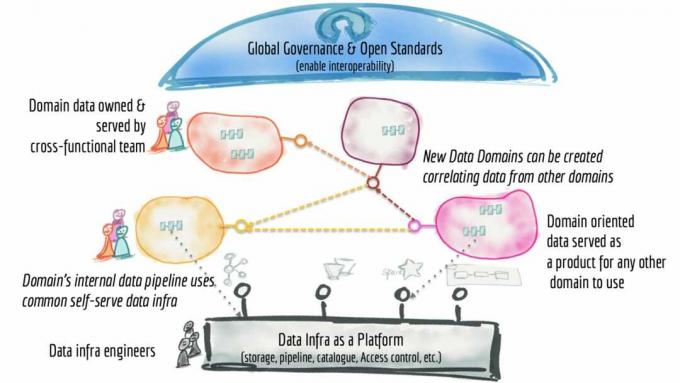
Първият принцип е за собственост на данните – трябва да е местно, да се намира в екипа, отговорен за събирането и/или използването на данните. Ако има централен принцип за мрежите от данни, това е той – контролът върху данните трябва да се прехвърли на домейна, който ги притежава. Мислете за домейна като за разширение на знанията за домейна – това е организационната единица или група от хора, които разбират какво представляват данните и как се отнасят към бизнеса. Това е субектът, който знае защо се събира наборът от данни; как се консумира и от кого; и как трябва да се управлява през жизнения му цикъл.
Нещата стават малко по-сложни за данни, които се споделят между домейни или когато данните под един домейн зависят от данни или API от други домейни. Добре дошли в реалния свят, където данните рядко са остров. Това е едно от местата, където внедряването на мрежи може да стане лепкаво.
Вторият принцип е, че данните трябва да се разглеждат като продукт. Това на практика е по-разширен поглед върху това, което се състои от обект с данни, тъй като той е нещо повече от част от данни или конкретен набор от данни и има повече поглед върху жизнения цикъл на това как данните могат и трябва да се обслужват и консумирани. И част от дефиницията на продукта е официална цел за ниво на обслужване, която може да се отнася до фактори като производителност, надеждност и надеждност, качество на данните, свързани със сигурността правила за оторизация и т.н На. Това е обещание, което домейнът, който притежава данните, дава на организацията.
По-конкретно, продуктът с данни надхвърля набора от данни или обекта от данни, за да включва кода за тръбопроводите за данни, необходими за генериране и/или трансформиране на данните; свързаните метаданни (които, разбира се, могат да обхванат всичко от дефиницията на схемата до съответния бизнес термини от речника, модели на потребление или форми като релационни таблици, събития, пакетни файлове, формуляри, графики, и т.н.); и инфраструктура (как и къде се съхраняват и обработват данните). Това има значителни организационни последици, като се има предвид, че изграждането на тръбопроводи за данни често е a несвързана дейност, управлявана независимо от практикуващи специалисти като инженери по данни и разработчици. Поне в матричен контекст те трябва да бъдат част от или свързани с домейна или бизнес екипа, който притежава данните.
Между другото, този продукт за данни трябва да отговаря на някои ключови изисквания. Данните трябва да са готови откриваем; Вероятно за това са каталозите. Също така трябва да бъде изследваем, позволявайки на потребителите да разбиват. И трябва да бъде адресируем; тук Dehghani споменава, че данните трябва да имат уникални канонични адреси, което звучи като абстракция от по-високо ниво, този семантичен уеб остатък, класически Ури. И накрая, данните трябва да бъдат разбираемо (Dehghani предлага "самоописваща семантика и синтаксис"); надежден; и сигурен. Нека не забравяме, че тъй като това е предназначено да пресича множество домейни, ще са необходими усилия за хармонизиране на данните.
Докато мрежата от данни не се дефинира от технологията, в реалния свят специфични инженерни групи ще притежават основната платформа за данни, независимо дали става дума за база данни, езеро от данни и/или двигател за стрийминг. Това важи независимо от това дали организацията внедрява тези платформи на място или се възползва от услугата за управлявана база данни в облака, и по-вероятно и на двете места. Някой трябва да притежава основната платформа и тези платформи също ще се считат за продукти в голямата схема на нещата.
Платформа за данни на самообслужване
Третият принцип е необходимостта данните да бъдат достъпни чрез платформа за данни на самообслужване както е показано по-горе. Разбира се, самообслужването се превърна в девиз за по-широк достъп до данни, тъй като това е единственият начин данните да станат консумативи, тъй като масивът от данни се разширява, като се има предвид, че ИТ ресурсите са ограничени, особено с инженерите на данни, които са рядкост и скъпоценен. Това, което тя описва тук, не трябва да се бърка с платформи за самообслужване за визуализация на данни или специалисти по данни; това е повече за разработчици на инфраструктура и продукти.
Тази платформа може да има, според термините на Dehghani, различни равнини (или кожи), които обслужват различни групи от практикуващи. Примерите могат да включват равнина за осигуряване на инфраструктура, която се занимава с цялата грозна физическа механика на маршалинг на данни (като осигуряване на съхранение; настройка на контроли за достъп; и машината за заявки); опит в разработването на продукти, който предоставя декларативен интерфейс за управление на жизнения цикъл на данните; и равнина за наблюдение, която управлява продуктите за данни. Dehghani става много по-изчерпателен за това какво трябва да поддържа платформата за данни за самообслужване и ето списъка.
И накрая, нито един подход за управление на данни не е пълен без управление. Това е четвъртият принцип и Дегани го нарича федеративно изчислително управление. Това признава реалността, че в една разпределена среда ще има множество взаимозависими продукти от данни, които трябва да взаимодействат и по този начин да поддържат мандатите за суверенитет на данните и съпътстващите правила за запазване на данни и достъп. Ще има нужда от пълно разбиране и проследяване на произхода на данните.
Една единствена публикация няма да оправдае тази тема. С риск да объркам идеята, това означава, че федерация от продукти за данни и данни собствениците на платформени продукти създават и налагат глобален набор от правила, приложими към всички продукти за данни и интерфейси. Това, което липсва тук, е, че трябва да има разпоредба за висшия мениджмънт, когато става въпрос за политики и мандати за цялото предприятие; Dehghani го прави извод (да се надяваме, че книгата й ще стане по-конкретна). По същество Дегани заявява това, което вероятно ще бъде неформална практика днес, където много ad hoc решения относно управлението вече се вземат на местно ниво.
Федерално изчислително управление
Така че трябва ли да опитате това у дома?
Малко теми са привлекли толкова внимание в света на данните през изминалата година, колкото мрежата от данни. Един от задействащите механизми е, че в един все по-облачен свят, където приложенията и бизнес логиката се разлагат на микроуслуги, защо да не третираме данните по същия начин?
Отговорът е по-лесно да се каже, отколкото да се направи. Например, докато монолитните системи могат да бъдат твърди и тромави, разпределените системи въвеждат свои собствени сложности, добре дошли или не. Съществува риск от създаване на нови силози, да не говорим за хаос, когато местното овластяване не е обмислено по подходящ начин.
Например, разработването на канали за данни трябва да бъде част от определението за продукт за данни, но когато тези тръбопроводи могат да бъдат използвани повторно другаде, трябва да се предвиди разпоредба екипите за продукти за данни да споделят своите IP. В противен случай има много дублирани усилия. Дегани призовава екипите да работят във федерална среда, но тук рискът е да стъпите на чужд терен.
Разпределянето на управлението на жизнения цикъл на данните може да е овластяващо, но в повечето организации вероятно ще има много случаи, в които собствеността върху данните не е ясна за сценарии, при които множество групи заинтересовани страни споделят използването или когато данните се извличат от нечии други данни. Dehghani признава това, като отбелязва, че домейните обикновено получават данни от множество източници и в от своя страна различни домейни могат да дублират данни (и да ги трансформират по различни начини) за свои собствени консумация.
Мрежите от данни като концепции са в процес на разработка. Във встъпителната си публикация Дегани се позовава на ключов подход за правене на данни откриваеми: чрез това, което тя нарича „самоописваща семантика“. Но нейното описание е кратко, което показва, че използването на „добре описан синтаксис“, придружен от примерни набори от данни, и спецификации за схема са добри отправни точки – за инженера на данни, не за бизнеса анализатор. Това е точка, която бихме искали да я видим ясно изразена в предстоящата й книга.
Друго ключово изискване, за обединено „изчислително“ управление, може да бъде пълна хапка за произнасяне, но ще бъде дори повече от това за прилагане, както се вижда от диаграмата по-горе. Локализиране на решения възможно най-близо до източника, докато глобализиране на решения относно оперативната съвместимост ще изисква значителни проби и грешки.
Всичко казано дотук, има добри причини да водим тази дискусия. Има прекъсвания на връзката с данни и много от проблемите едва ли са нови. Централизираната архитектура, като корпоративно хранилище за данни, езеро с данни или езеро с данни, не може да се отдаде на справедливост в света на полиглотите. От друга страна, могат да бъдат направени аргументи за подхода на структурата на данни, който поддържа, че един по-централизиран подход към управлението на метаданни и откриването на данни ще бъде по-ефективен. Може да се направи и хибриден подход, който използва силата на обединените метаданни управлението на структурата на данни може да се използва като логическа опорна плата за домейни за изграждане и притежаване на техните данни продукти.
Друга болезнена точка е, че процесите за обработка на данни на всеки етап от техния жизнен цикъл често са несвързани, където инженерите по данни или разработчиците на приложения, изграждащи тръбопроводи, могат да бъдат отделени от линейните организации, които данните служи. Самообслужването стана популярно сред бизнес анализаторите за визуализация и за учените по данни при разработването на ML модели и преместването им в производство. Има добра причина да се разшири това до управление на жизнения цикъл на данните до екипи, които по всякаква логика трябва да притежават данните.
Но нека не изпреварваме. Това е много амбициозно нещо. Когато става въпрос за разпределяне на управлението и собствеността върху активите с данни, както споменахме по-рано, дяволът е в детайлите. И има много детайли, които все още трябва да бъдат изгладени. Все още не сме продадени, че подобни подходи отдолу нагоре за притежаване на данни ще се разпространят в цялата корпоративна база данни и че може би трябва да се насочим по-скромно: да ограничим мрежата до части от организацията със свързани или взаимозависими домейни.
Виждаме се няколко публикации където клиентите преждевременно обявяват победа. Но като тази публикация щати, само защото вашата организация е внедрила обединен слой на заявка или е сегментирала своите езера от данни, не прави нейното внедряване мрежа от данни. На този етап прилагането на мрежа от данни с цялото й разпределено управление трябва да се третира като доказателство за концепцията.
Голяма информация
- Как да разберете дали сте замесени в нарушение на сигурността на данните (и какво да направите след това)
- Борбата с пристрастията в AI започва с данните
- Справедлива прогноза? Как 180 метеоролози предоставят „достатъчно добри“ данни за времето
- Терапиите за рак зависят от шеметни количества данни. Ето как се сортира в облака