I løbet af det seneste år har få emner trukket mere diskussion i dataverdenen end datamasker. Spørgsmålet er, om datamasker er klar til bedste sendetid.
Data Mesh
At centralisere eller distribuere datahåndtering? Det spørgsmål har været på forbrændingen lige siden afdelingsminicomputere invaderede virksomheden, efterfulgt endnu mere subversivt af pc'er og LAN'er, der gik gennem bagdøren. Og konventionel visdom har svinget frem og tilbage lige siden. Arbejdsgruppe- eller afdelingssystemer for at gøre data tilgængelige, derefter konsolidering af virksomhedsdatabaser for at slippe af med al duplikeringen.
Kan du huske, da datasøen skulle være sluttilstanden? Ligesom virksomhedens datavarehus før det, forestillingen om, at alle data kunne rulle sammen ét sted, så der var kun en enkelt kilde til sandhed, som alle samfundslag på tværs af virksomheden kunne få adgang til bevist urealistisk. Internettets forbindelse, den tilsyneladende billige lagring og endeløse skalerbarhed i skyen eksplosion af smartenheder og IoT-data truer med at overvælde datavarehusene og datasøerne så møjsommeligt Opsætning.
Data søhuse er på det seneste dukket op for at bringe det bedste fra begge verdener, mens datastrukturer og intelligente datahubs optimerer afvejningen mellem virtualisering og replikering af data.Det ville være meningsløst at sige, at ethvert af disse alternativer tilbyder den definitive sølvkugle.
Indtast Data Mesh
I løbet af det seneste år er der dukket en ny teori op, der anerkender nytteløsheden af top-down eller monolitiske tilgange til datastyring: datanettet. Mens meget af søgelyset på det seneste har været på AI og maskinlæring, er der i dataverdenen færre emner, der er trækker mere diskussion end data mesh. Bare se på Google Trends-data for de seneste 90 dage: søgninger efter Data Mesh er langt flere end dem efter Data Lakehouse.
Det er opstået af Zhamak Dehghani, direktør for next tech incubation kl Thoughtworks Nordamerika, gennem et omfattende sæt værker, der begynder med en introduktion tilbage i 2019, en drill-down på principper og logisk arkitektur i slutningen af 2020, det vil snart kulminere i en bog (hvis du er interesseret, Starburst data tilbyder et smugkig). Datamasker har ofte været sammenlignet med datavæv, men en nærlæsning af Dehghanis arbejde afslører, at dette handler mere om proces end teknologi, som James Serra, en arkitekturleder hos EY og tidligere hos Microsoft, korrekt påpegede i et blogindlæg. Ikke desto mindre er emnet datamasker (som er distribuerede visninger af dataejendommen) vs. datastrukturer (som anvender mere centraliserede tilgange) fortjener sin egen stilling, da interesse for begge dele har været ret ens.
Enkelt sagt, hvis det er muligt, er datanetværk ikke en teknologistak eller fysisk arkitektur. Data mesh er en proces- og arkitektonisk tilgang, der uddelegerer ansvaret for specifikke datasæt til domæner eller områder af virksomheden, der har den nødvendige faglige ekspertise til at vide, hvad dataene skal repræsentere, og hvordan de skal være Brugt.
Der er et arkitektonisk aspekt ved dette: i stedet for at antage, at data vil ligge i en datasø, vil hvert "domæne" være ansvarligt for at vælge, hvordan de skal hoste og betjene de datasæt, de ejer.
Udover ekstern regulering eller corporate governance-politik er domænerne årsagen til, at specifikke datasæt indsamles. Men djævelen er i detaljerne, og dem er der mange af.
Så datanettet er ikke defineret af datavarehuset, datasøen eller datasøen, hvor dataene fysisk befinder sig. Det er heller ikke defineret af dataføderationen, dataintegrationen, forespørgselsmotoren eller katalogiseringsværktøjer, der udfylder og anmærker disse datalagre. Selvfølgelig, det har ikke stoppet teknologileverandører fra data mesh vask deres produkter. I løbet af det næste år vil vi sandsynligvis se udbydere af kataloger, forespørgselsmotorer, datapipelines og styring male deres værktøjer eller platforme i et datamesh-lys. Men som du ser markedsføringsbudskaberne, så husk, at datamasker handler om proces og hvordan du implementerer teknologi. For eksempel er en fødereret forespørgselsmotor simpelthen en aktiverer, der kan hjælpe et team med implementeringen, men som i sig selv ikke pludselig forvandler et dataområde til et datanet.
Kernepillerne
Data Mesh er et komplekst koncept, men den bedste måde at starte på er ved at forstå principperne bag det.
Det første princip handler om dataejerskab – det skal være lokalt og være hjemmehørende hos det team, der er ansvarligt for at indsamle og/eller forbruge dataene. Hvis der er et centralt princip for datamasker, er det det – det er, at kontrollen af data skal overdrages til det domæne, der ejer dem. Tænk på et domæne som en forlængelse af domæneviden - dette er den organisatoriske enhed eller gruppe af mennesker, der forstår, hvad data er, og hvordan det relaterer til virksomheden. Dette er den enhed, der ved, hvorfor datasættet bliver indsamlet; hvordan det forbruges, og af hvem; og hvordan det skal styres gennem dets livscyklus.
Tingene bliver lidt mere komplicerede for data, der deles på tværs af domæner, eller hvor data under ét domæne er afhængige af data eller API'er fra andre domæner. Velkommen til den virkelige verden, hvor data sjældent er en ø. Dette er et af de steder, hvor implementering af masker kan blive klistret.
Det andet princip er, at data skal betragtes som en produkt. Det er i virkeligheden et mere ekspansivt syn på, hvad der omfatter en dataentitet, idet det er mere end en del af data eller et specifikt datasæt og tager mere et livscyklussyn på, hvordan data kan og bør serveres og forbruges. Og en del af definitionen af produktet er et formelt serviceniveaumål, som kan vedrøre faktorer såsom ydeevne, troværdighed og pålidelighed, datakvalitet, sikkerhedsrelaterede autorisationsregler og så på. Det er et løfte, som domænet, der ejer dataene, giver organisationen.
Specifikt går et dataprodukt ud over datasættet eller dataenheden til at inkludere koden for de datapipelines, der er nødvendige for at generere og/eller transformere dataene; de tilhørende metadata (som selvfølgelig kunne omfatte alt fra skemadefinition til relevant forretning ordlisteudtryk, forbrugsmodeller eller -former såsom relationelle tabeller, begivenheder, batchfiler, formularer, grafer, etc.); og infrastruktur (hvordan og hvor dataene opbevares og behandles). Dette har betydelige organisatoriske konsekvenser, da opbygningen af datapipelines ofte er en usammenhængende aktivitet håndteret uafhængigt af specialister såsom dataingeniører og udviklere. I det mindste i en matrixsammenhæng skal de være en del af eller associeret med domænet eller forretningsteamet, der ejer dataene.
På og i øvrigt skal det dataprodukt opfylde nogle nøglekrav. Data skal være let kan opdages; det er formentlig hvad kataloger er til. Det burde det også være udforskeligt, gør det muligt for brugerne at bore ned. Og det burde det være adresserbar; her nævner Dehghani, at data skal have unikke kanoniske adresser, hvilket lyder som en abstraktion på højere niveau, den semantiske webrest, klassiske Uri. Endelig bør data være forståeligt (Dehghani foreslår "selv-beskrivende semantik og syntaks"); troværdig; og sikker. Lad os ikke glemme, at da dette er beregnet til at krydse flere domæner, vil det være nødvendigt at arbejde med dataharmonisering.
Selvom datamesh ikke er defineret af teknologi, vil specifikke ingeniørgrupper i den virkelige verden eje den underliggende dataplatform, uanset om det er en database, datasø og/eller streamingmotor. Det gælder, uanset om organisationen implementerer disse platforme på stedet eller udnytter en administreret databasetjeneste i skyen, og mere sandsynligt begge steder. Nogen skal eje den underliggende platform, og disse platforme vil også blive betragtet som produkter i den store sammenhæng.
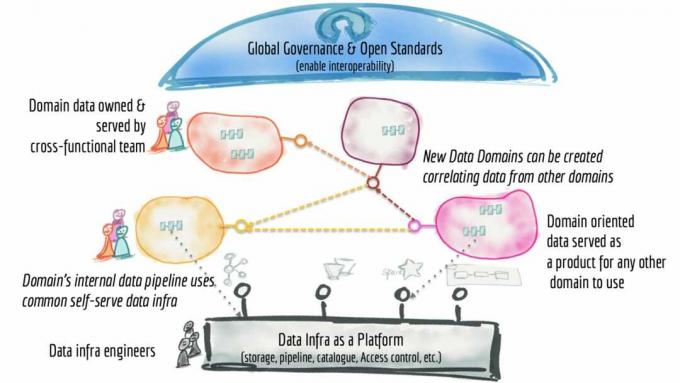
Selvbetjeningsdataplatform
Det tredje princip er behovet for, at data er tilgængelige via en selvbetjeningsdataplatform som vist ovenfor. Selvfølgelig er selvbetjening blevet et kodeord for bredere dataadgang, da det er den eneste måde for data at blive kan forbruges, efterhånden som dataområdet udvides, da IT-ressourcerne er begrænsede, især med dataingeniører, der er sjældne og kostbar. Det, hun beskriver her, må ikke forveksles med selvbetjeningsplatforme til datavisualisering eller dataforskere; denne er mere til infrastruktur- og produktudviklere.
Denne platform kan have, hvad Dehghani betegner, forskellige fly (eller skins), der betjener forskellige dele af udøvere. Eksempler kunne omfatte et infrastrukturforsyningsplan, der håndterer al den grimme fysiske mekanik ved at samle data (såsom klargøring af opbevaring; indstilling af adgangskontrol; og forespørgselsmotoren); en produktudviklingsoplevelse, der giver en deklarativ grænseflade til styring af datalivscyklussen; og et supervisionsplan, der styrer dataprodukterne. Dehghani bliver meget mere udtømmende om, hvad en selvbetjent dataplatform skal understøtte, og her er listen.
Endelig er ingen tilgang til håndtering af data komplet uden styring. Det er det fjerde princip, og Dehghani betegner det fødereret computerstyring. Dette anerkender den virkelighed, at der i et distribueret miljø vil være flere, indbyrdes afhængige dataprodukter, der skal fungere sammen, og derved understøtte datasuverænitetsmandater og de tilhørende regler for dataopbevaring og adgang. Der vil være behov for fuldt ud at forstå og spore dataafstamning.
Et enkelt indlæg ville ikke yde dette emne retfærdighed. Med fare for at bastardisere ideen betyder det, at en sammenslutning af dataprodukter og data platformproduktejere skaber og håndhæver et globalt sæt regler, der gælder for alle dataprodukter og grænseflader. Det, der mangler her, er, at der skal være mulighed for topledelse, når det kommer til virksomhedsdækkende politikker og mandater; Dehghani udleder det (forhåbentlig bliver hendes bog mere specifik). I det væsentlige angiver Dehghani, hvad der sandsynligvis vil være uformel praksis i dag, hvor der allerede træffes en masse ad hoc-beslutninger om regeringsførelse på lokalt niveau.
Federated Computational Governance
Så skal du prøve dette derhjemme?
Få emner har tiltrukket sig så meget opmærksomhed i dataverdenen i løbet af det seneste år som datanettet. En af triggerne er, at i en stadig mere cloud-native verden, hvor applikationer og forretningslogik bliver dekomponeret til mikrotjenester, hvorfor så ikke behandle data på samme måde?
Svaret er lettere sagt end gjort. For eksempel, mens monolitiske systemer kan være stive og uhåndterlige, distribuerede systemer introducerer deres egne kompleksiteter, velkommen eller ej. Der er risiko for at skabe nye siloer, for ikke at tale om kaos, når lokal empowerment ikke er tilstrækkeligt gennemtænkt.
For eksempel skal udvikling af datapipelines være en del af definitionen af et dataprodukt, men når disse pipelines kan genbruges andre steder, skal der sørges for, at dataproduktteams kan dele deres IP. Ellers er der masser af dobbeltarbejde. Dehghani opfordrer hold til at operere i et forbundsmiljø, men her er risikoen at træde på en andens græstæppe.
Distribution af livscyklusstyringen af data kan være styrkende, men i de fleste organisationer vil der sandsynligvis være masser af tilfælde, hvor ejerskab af data er ikke entydigt for scenarier, hvor flere interessentgrupper enten deler brug, eller hvor data stammer fra en andens data. Dehghani anerkender dette og bemærker, at domæner typisk får data fra flere kilder, og i Forskellige domæner kan duplikere data (og transformere dem på forskellige måder) til deres egne forbrug.
Datamasker som koncepter er igangværende arbejde. I sit indledende indlæg refererer Dehghani til en nøgletilgang til at gøre data synlige: gennem det, hun betegner som "selvbeskrivende semantik." Men hendes beskrivelse er kort, angiver, at brug af "velbeskrevet syntaks" ledsaget af eksempeldatasæt og specifikationer for skema er gode udgangspunkter -- for dataingeniøren, ikke for virksomheden analytiker. Det er et punkt, vi gerne vil se hendes kød ud i hendes kommende bog.
Et andet nøglekrav, for fødereret "beregningsmæssig" styring, kan være en mundfuld at udtale, men det vil være endnu mere af det at implementere, som et kig på diagrammet ovenfor illustrerer. Lokalisering af beslutninger så tæt på kilden, mens globalisering af beslutninger vedrørende interoperabilitet vil kræve betydelige forsøg og fejl.
Når det er sagt, er der gode grunde til, at vi har denne diskussion. Der er afbrydelser med data, og mange af problemerne er næppe nye. Centraliseret arkitektur, såsom et virksomhedsdatavarehus, datasø eller datasøhus, kan ikke yde retfærdighed i en polyglot-verden. På den anden side kan der argumenteres for datastrukturtilgangen, der fastholder, at en mere centraliseret tilgang til metadatastyring og dataopdagelse vil være mere effektiv. Der er også tale om en hybrid tilgang, der udnytter kraften i forenede metadata styring af datastrukturen kunne bruges som en logisk backplane for domæner til at bygge og eje deres data Produkter.
Et andet smertepunkt er, at processerne til håndtering af data på hvert trin af dens livscyklus ofte er usammenhængende, hvor dataingeniører eller app-udviklere, der bygger pipelines, kan blive skilt fra linjeorganisationerne, som dataene tjener. Selvbetjening er blevet populært blandt forretningsanalytikere til visualisering og for datavidenskabsfolk til at udvikle ML-modeller og flytte dem i produktion. Der er gode argumenter for at udvide dette til at administrere datalivscyklussen til teams, der efter al logik burde eje dataene.
Men lad os ikke komme os selv foran. Det er meget ambitiøse ting. Når det kommer til at fordele forvaltningen og ejerskabet af dataaktiver, som tidligere nævnt, er djævelen i detaljerne. Og der er masser af detaljer, der stadig skal stryges ud. Vi er endnu ikke solgt til, at sådanne bottom-up tilgange til at eje data vil skalere på tværs af hele virksomhedens dataområde, og at måske skulle vi sigte mere beskedent: begrænse masken til dele af organisationen med relaterede eller indbyrdes afhængige domæner.
Vi ser flere indlæg hvor kunderne erklærer for tidligt sejr. Men som dette indlæg stater, blot fordi din organisation har implementeret et fødereret forespørgselslag eller segmenteret dets datasøer, gør det ikke dets implementering til et datamesh. På dette tidspunkt bør implementering af et datanet med hele dets distribuerede styring behandles som proof of concept.
Big Data
- Sådan finder du ud af, om du er involveret i et databrud (og hvad du skal gøre nu)
- Bekæmpelse af bias i AI starter med dataene
- Fair prognose? Hvordan 180 meteorologer leverer 'godt nok' vejrdata
- Kræftbehandlinger afhænger af svimlende mængder af data. Sådan er det sorteret i skyen