Die neuartige Architektur des Chip-Startups verspricht, das Training neuronaler Netze schneller und einfacher zu machen.
Die rasante Entwicklung des Deep Learning hat ein KI-Wettrüsten ausgelöst. Letztes Jahr haben Risikokapitalgeber mehr als 1,5 Milliarden US-Dollar in Halbleiter-Start-ups gesteckt, und das gibt es Mittlerweile entwickeln etwa 45 Unternehmen Chips speziell für Aufgaben der künstlichen Intelligenz entwickelt, einschließlich Google mit seiner Tensor Processing Unit (TPU). Nachdem eines dieser Startups, Wave Computing, sein „Early Access“-System fast ein Jahr lang in aller Stille getestet hat, steht es kurz vor der Ankündigung seines ersten kommerziellen Produkts. Und es ist vielversprechend, dass ein neuartiger Ansatz sowohl hinsichtlich der Leistung als auch der Benutzerfreundlichkeit beim Training neuronaler Netze große Fortschritte bringen wird.
„Eine Reihe von Unternehmen werden TPU-Nachahmungen haben, aber das ist nicht das, was wir tun – das war ein mehrjähriger, mehrjähriger Prozess.“ „Wir haben Millionen von Dollar investiert, um eine völlig neue Architektur zu entwickeln“, sagte CEO Derek Meyer in einem Interview. „Einige der Ergebnisse sind einfach wirklich erstaunlich.“
Mit Ausnahme der TPUs von Google wird der Großteil des Trainings derzeit auf Standard-Xeon-Servern durchgeführt, die zur Beschleunigung Nvidia-GPUs verwenden. Die Datenflussarchitektur von Wave ist anders. Die Dataflow Processing Unit (DPU) benötigt keine Host-CPU und besteht aus Tausenden winziger, Selbstzeitgesteuerte Verarbeitungselemente, die für die 8-Bit-Ganzzahloperationen konzipiert sind, die üblicherweise in neuronalen Systemen verwendet werden Netzwerke.
Letzte Woche gab das Unternehmen bekannt, dass es in zukünftigen Designs 64-Bit-MIPS-Kerne verwenden wird, allerdings eigentlich für den Haushalt. Das Wave-Board der ersten Generation verwendet für diese Aufgaben bereits einen Andes N9 32-Bit-Mikrocontroller, sodass MIPS64 ein Upgrade sein wird, das es geben wird Der Systemagent verfügt über denselben 64-Bit-Adressraum wie die DPU sowie Unterstützung für Multithreading, sodass Aufgaben auf ihrer eigenen Logik ausgeführt werden können Prozessoren. (Meyer und andere im Managementteam haben zuvor bei MIPS gearbeitet, und Wave wird teilweise von unterstützt Tallwood, die gleiche Risikokapitalgesellschaft, die MIPS kürzlich für 65 US-Dollar von Imagination Technologies erworben hat Million.)
Aber das ist für zukünftige Prozessoren. Das aktuelle Design besteht aus Tausenden unabhängigen Verarbeitungselementen, jedes mit eigenem Befehlsspeicher, Datenspeicher, Registern und einer 8-Bit-Logikeinheit. Diese sind in Cluster gruppiert, die jeweils 16 Verarbeitungselemente und zusätzliche Recheneinheiten, darunter zwei, enthalten 32-Bit-MAC-Einheiten (Multiply-Accumulate), die einige der wichtigsten arithmetischen Funktionen in Faltungs-Neuronalen Netzwerken ausführen (CNNs).
Die von TSMC im 16-nm-Verfahren hergestellte Dataflow Processing Unit (DPU) enthält 1.024 dieser Cluster für insgesamt 16.384 Verarbeitungselemente mit Mesh-Verbindung. Diese sind in einem Array aus 24 Rechenmaschinen mit jeweils 32 oder 64 Clustern und einem Bus gruppiert, der die Verbindung zum Speicher und zur E/A herstellt. Es verfügt über eine Spitzenkapazität von 181 Billionen 8-Bit-Integer-Operationen pro Sekunde, aber die 2.048 MAC-Einheiten (8 Billionen MACs pro Sekunde) sollten bis zu 16 Teraops liefern.
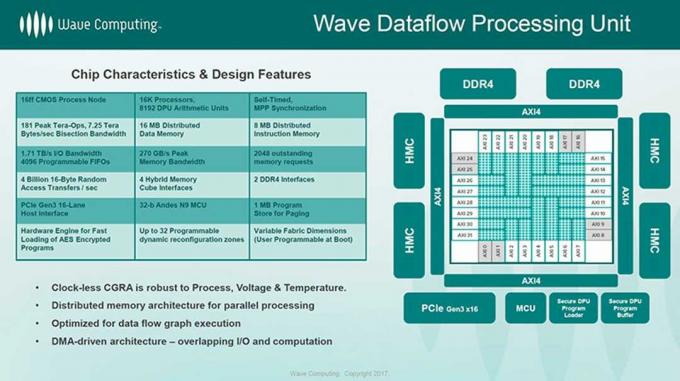
Waves Ziel ist es nicht, diese Chips zu verkaufen. Stattdessen möchte es ein vollständiges KI-System bereitstellen. Das Beta-Board verfügt über vier DPUs (65.536 Verarbeitungselemente), 256 GB DDR4-Systemspeicher und 8 GB DRAM mit hoher Bandbreite (vier 2 GB Hybrid Memory Cube-Stacks). Ein PCI-Express-Switch verbindet es mit anderen Karten sowie dem Systemagenten. Vier davon sind in einem 3U-Rackgehäuse verpackt und ein einzelner Knoten kann bis zu vier dieser Wave Compute Appliances enthalten mit mehr als einer Million Verarbeitungselementen, 8 TB DRAM und 128 GB HMC-Speicher für eine Spitzenkapazität von 11,6 petaops. Ein Host-Linux-Server verwaltet Sitzungen über mehrere Knoten hinweg.
Es ist ein beeindruckendes Design, aber Meyer deutete an, dass die kommerzielle Version ganz anders aussehen wird. Möglicherweise handelt es sich überhaupt nicht um einen Rackmount-Server. Eine Möglichkeit besteht darin, dass Wave sich für eine Workstation nach dem Vorbild der Nvidia DGX1 Station entscheidet, die über vier verfügt Tesla V100-GPUs. Wave könnte seine DPUs auch als Dienst über die Cloud verfügbar machen, entweder allein oder mit einem Partner.
Unabhängig davon, wie es von außen aussieht, wird das erste Produkt von Wave im Inneren ein Test einer ganz anderen Architektur sein. Wie der Name schon sagt, konzentriert sich die Datenflussarchitektur darauf, Daten schnell durch ein Prozessor-Array zu bewegen, anstatt eine Reihe von Anweisungen nacheinander auszuführen. Die Wave-DPU benötigt keine Host-CPU und verfügt über kein Betriebssystem oder Anwendungen. Im Gegensatz zu einer CPU, die Anweisungen außerhalb der Reihenfolge ausführen und Anweisungen kombinieren kann, verfügt die DPU über keine globale Uhr und ist statisch geplant. Da es keinen gemeinsamen Cache gibt, müssen Sie sich keine Sorgen um die Aufrechterhaltung der Kohärenz machen.
Um ein neuronales Netzwerk auszuführen, zerlegt der Wave-Compiler es in eine Reihe von Schritten und weist diese Gruppen von Verarbeitungselementen zu, wo sie im lokalen Befehlsspeicher gespeichert werden. Wenn Daten vom DRAM oder den HMC-Stacks in die DPU geladen werden, führt die asynchrone Logik sofort eine Operation aus und gibt das Ergebnis dann an benachbarte Verarbeitungselemente weiter. Der Prozess wird fortgesetzt, bis keine Daten mehr vorhanden sind. Anschließend geht der Cluster in den Ruhezustand.
Dieses äußerst einfache Design bietet eine Reihe von Vorteilen für Deep Learning. Dadurch können die Verarbeitungselemente mit viel höheren Geschwindigkeiten laufen. Die selbstgesteuerte Logik ist theoretisch in der Lage, 10 GHz zu erreichen, obwohl Wave sagt, dass sie in der Praxis bei etwa 6,7 GHz arbeiten wird. Es reduziert auch die Die Chipfläche ermöglicht es Wave, Tausende von Verarbeitungselementen auf einem einzigen Chip zu packen, ohne auf dem neuesten Stand des Prozesses bleiben zu müssen Technologie.
All dies hängt jedoch von einem guten Compiler ab, der vorhandene Modelle übernehmen und Aufgaben Tausenden von Verarbeitungselementen auf eine Weise zuweisen kann, die die Datenflussarchitektur maximiert. Derzeit funktionieren die DPU und die Software mit dem TensorFlow-Framework von Google, obwohl Wave auch darüber gesprochen hat, Unterstützung für Microsoft Cognitive Toolkit und MXNet, Amazons bevorzugtes Tool für AWS, hinzuzufügen.
Während Wave um aktuelle Benutzer konkurrieren wird, die bereits mit diesen Frameworks arbeiten, scheint sein eigentliches Ziel darin zu bestehen, Organisationen zu erreichen, die noch keine künstliche Intelligenz nutzen. „Es gibt einen viel größeren Markt an Unternehmen, die kein Deep Learning nutzen, und das ist eine große Chance für uns“, sagte Meyer. „Für Unternehmen, die noch keine KI nutzen, eröffnen sich dadurch ganz neue Anwendungsfälle.“ Wave schlug das Design, den Preis und die Benutzerfreundlichkeit vor Die Nutzung des Systems wird dazu beitragen, neue Benutzer für KI zu gewinnen, aber wir müssen natürlich auf Details zum kommerziellen Produkt warten.
Letztendlich muss es auch wettbewerbsfähige Leistungen erbringen. Als Wave die DPU erstmals auf der Linley Processor Conference im Jahr 2016 vorstellte, war von einer zehnfachen Geschwindigkeitssteigerung gegenüber modernen GPUs die Rede. Mehr Vor kurzem hat Wave eine bis zu 1.000-mal bessere Leistung als aktuelle CPUs, GPUs und FPGAs (eine relativ breite Palette von) versprochen Fähigkeiten). Es wurden auch einige Testergebnisse gezeigt, bei denen ein einzelner Knoten (64 DPUs) auf mehreren CNNs zur Bilderkennung verwendet wurde, sowie a Recurrent Neural Network (RNN) für maschinelle Übersetzung, was darauf hinweist, dass es in der Lage ist, komplexe neuronale Netze zu trainieren Std. Meyer sagte, dass Wave auf dem richtigen Weg sei, das von ihm versprochene Leistungsniveau zu liefern und „und vielleicht sogar darüber hinaus“ mit dem kommerziellen System.