За останній рік небагато тем викликали більше дискусій у світі даних, ніж сітки даних. Питання в тому, чи готові сітки даних до прайм-тайму.
Сітка даних
Централізувати чи розподілити керування даними? Це питання було на передньому плані з тих пір, як відомчі міні-комп’ютери вторглися на підприємство, а за ними ще більш підривно — ПК і локальні мережі, що пройшли через чорний хід. І з тих пір традиційна мудрість коливалася туди-сюди. Системи робочих груп або відділів, щоб зробити дані доступними, а потім консолідації корпоративних баз даних, щоб позбутися всього дублювання.
Пам’ятаєте, коли озеро даних мало бути кінцевим станом? Так само, як сховище корпоративних даних до нього, ідея, що всі дані можуть згортатися в одному місці, щоб існувало лише одне джерело правди, до якого мали доступ усі верстви суспільства на підприємстві нереально. Підключення до Інтернету, здавалося б, дешеве сховище та нескінченна масштабованість хмари вибух інтелектуальних пристроїв і даних IoT загрожує переповнити сховища даних і озера даних настільки важко налаштувати.
Data lakehouses нещодавно з’явилися, щоб поєднати найкраще з обох світів, тоді як структури даних та інтелектуальні концентратори даних оптимізують компроміс між віртуалізацією та реплікацією даних.Було б безглуздо стверджувати, що будь-яка з цих альтернатив пропонує остаточну срібну кулю.
Введіть Data Mesh
За останній рік з’явилася нова теорія, яка визнає безглуздість монолітних або низхідних підходів до управління даними: сітка даних. Хоча останнім часом більшість уваги прикута до ШІ та машинного навчання, у світі даних залишається менше тем, які малюнок більше обговорення ніж сітка даних. Просто подивіться на дані Google Trends за останні 90 днів: кількість пошуків Data Mesh набагато перевищує кількість пошуків Data Lakehouse.
Він був створений Жамак Дехгані, директор Next Tech Incubation at Thoughtworks Північна Америка, через великий набір робіт, починаючи зі вступу ще в 2019 році, деталізація принципів і логічної архітектури наприкінці 2020 року, що незабаром досягне кульмінації в книзі (якщо вам цікаво, Дані Starburst пропонує швидкий погляд). Меші даних часто були порівняно з матеріалами даних, але уважне ознайомлення з роботою Дегані показує, що це більше стосується процесу, ніж технології, як правильно зазначив Джеймс Серра, керівник відділу архітектури в EY, який раніше працював у Microsoft у дописі в блозі. Тим не менш, тема сіток даних (які є розподіленими представленнями масиву даних) проти. структури даних (які застосовують більш централізовані підходи) заслуговують на окрему посаду, оскільки інтерес до обох було досить схожим.
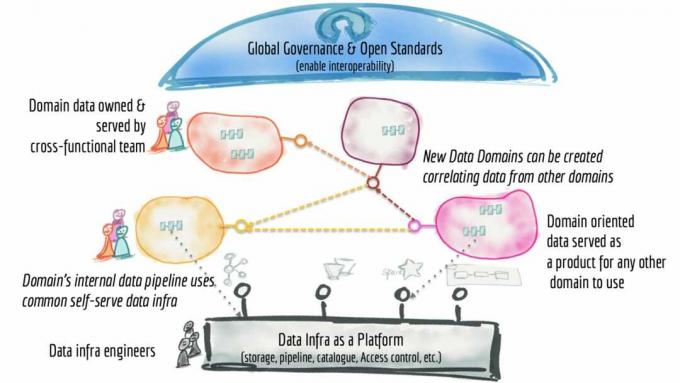
Простіше кажучи, якщо це можливо, сітка даних є ні технологічний стек або фізична архітектура. Сітка даних – це процес і архітектурний підхід, який делегує відповідальність за певні набори даних доменам або областям бізнес, який має необхідний предметний досвід, щоб знати, що мають представляти дані та як це має бути використовується.
У цьому є архітектурний аспект: замість припущення, що дані будуть зберігатися в озері даних, кожен «домен» відповідатиме за вибір способу розміщення та обслуговування наборів даних, якими вони володіють.
Окрім зовнішнього регулювання чи політики корпоративного управління, домени є причиною збору певних наборів даних. Але диявол криється в деталях, а їх дуже багато.
Отже, сітка даних не визначається сховищем даних, озером даних або озером даних, де фізично знаходяться дані. Він також не визначається об’єднанням даних, інтеграцією даних, механізмом запитів або інструментами каталогізації, які заповнюють і анотують ці сховища даних. Звичайно, це не зупинило постачальників технологій від дані промивання сітки свою продукцію. Протягом наступного року ми, імовірно, побачимо, як постачальники каталогів, механізмів запитів, конвеєрів даних і управління малюватимуть свої інструменти або платформи в світлі сітки даних. Але, коли ви бачите маркетингові повідомлення, пам’ятайте, що сітки даних стосуються процесу та способу впровадження технології. Наприклад, механізм об’єднаних запитів — це просто інструмент, який може допомогти команді з впровадженням, але сам по собі не перетворює масив даних раптово на мережу даних.
Основні стовпи
Data Mesh — це складна концепція, але найкращий спосіб почати — це зрозуміти принципи, що лежать в її основі.
Перший принцип стосується право власності на дані – він має бути локальним і перебувати в команді, відповідальній за збір та/або використання даних. Якщо є центральний принцип для сіток даних, то це він – це те, що контроль над даними повинен передаватися домену, який ними володіє. Подумайте про домен як про розширення знань про домен – це організаційна одиниця або група людей, які розуміють, що таке дані та як вони пов’язані з бізнесом. Це суб’єкт, який знає, для чого збирається набір даних; як споживається і ким; і як ним слід керувати протягом життєвого циклу.
Справи стають дещо складнішими для даних, які спільно використовуються між доменами, або коли дані в одному домені залежать від даних або API з інших доменів. Ласкаво просимо в реальний світ, де дані рідко є островом. Це одне з тих місць, де реалізація сіток може стати липкою.
Другий принцип полягає в тому, що дані слід розглядати як продукт. Це, по суті, більш розширений погляд на те, що складається з сутності даних, оскільки це більше, ніж частина даних або конкретного набору даних і більше розглядає життєвий цикл того, як дані можуть і повинні обслуговуватися та споживається. Частиною визначення продукту є формальна мета рівня обслуговування, яка може стосуватися факторів продуктивність, достовірність і надійність, якість даних, пов’язані з безпекою правила авторизації тощо на. Це обіцянка, яку домен, якому належать дані, дає організації.
Зокрема, продукт даних виходить за рамки набору даних або сутності даних, щоб включати код для конвеєрів даних, необхідних для створення та/або перетворення даних; пов’язані метадані (які, звичайно, можуть охоплювати все, від визначення схеми до відповідного бізнесу терміни глосарію, моделі споживання або форми, такі як реляційні таблиці, події, пакетні файли, форми, графіки, тощо); та інфраструктура (як і де дані зберігаються та обробляються). Це має значні організаційні наслідки, враховуючи, що створення конвеєрів даних часто є a неузгоджена діяльність, яка здійснюється незалежно фахівцями-практиками, такими як інженери даних та розробників. Принаймні в матричному контексті вони мають бути частиною або пов’язані з доменом або бізнес-групою, яка володіє даними.
До речі, цей продукт даних має відповідати деяким ключовим вимогам. Дані повинні бути доступними відкритий; мабуть, саме для цього і потрібні каталоги. Це теж має бути досліджувані, дозволяючи користувачам деталізувати. Так і повинно бути адресний; тут Дегані згадує, що дані повинні мати унікальні канонічні адреси, що звучить як абстракція вищого рівня, що семантичний веб-залишок, класичний Урі. Нарешті, дані повинні бути зрозуміло (Дегані пропонує «семантику та синтаксис самоопису»); надійний; і безпечний. Не забуваймо, що, оскільки це призначено для перетину кількох доменів, знадобляться зусилля щодо гармонізації даних.
Хоча сітка даних не визначається технологією, у реальному світі певні інженерні групи будуть володіти основною платформою даних, будь то база даних, озеро даних і/або потоковий механізм. Це стосується незалежно від того, чи впроваджує організація ці платформи локально чи користується перевагами служби керованої бази даних у хмарі, і, швидше за все, в обох місцях. Хтось повинен володіти основною платформою, і ці платформи також будуть вважатися продуктами, у великій схемі речей.
Платформа даних самообслуговування
Третій принцип полягає в тому, що дані повинні бути доступними через платформа даних самообслуговування як показано вище. Звичайно, самообслуговування стало девізом ширшого доступу до даних, оскільки це єдиний спосіб отримати дані витратні матеріали, оскільки обсяг даних розширюється, враховуючи, що ІТ-ресурси обмежені, особливо з інженерами даних, які рідко і дорогоцінний. Те, що вона тут описує, не слід плутати з платформами самообслуговування для візуалізації даних або дослідниками даних; цей більше для розробників інфраструктури та продуктів.
Ця платформа може мати різні плани (або скіни), які обслуговують різні групи практикуючих. Приклади можуть включати площину забезпечення інфраструктури, яка має справу з усією потворною фізичною механікою маршалінгу даних (наприклад, забезпечення зберігання; налаштування контролю доступу; і механізм запитів); досвід розробки продукту, який забезпечує декларативний інтерфейс для керування життєвим циклом даних; і площину спостереження, яка керує продуктами даних. Dehghani стає набагато більш вичерпним щодо того, що повинна підтримувати платформа даних для самообслуговування ось список.
Нарешті, жоден підхід до управління даними не є повним без управління. Це четвертий принцип, і Дегані його називає федеративне обчислювальне управління. Це підтверджує реальність того, що в розподіленому середовищі буде кілька взаємозалежних продуктів даних, які повинні взаємодіяти, і таким чином підтримувати мандати суверенітету даних і супутні правила для зберігання даних і доступу. Буде потрібно повністю зрозуміти та відстежити походження даних.
Одна публікація не доповнить цю тему. Ризикуючи спотворити цю ідею, це означає, що об’єднання даних і продуктів власники продуктів платформи створюють і забезпечують дотримання глобального набору правил, які застосовуються до всіх продуктів даних і інтерфейси. Чого тут не вистачає, так це того, що має бути положення для вищого керівництва, коли мова йде про політику та повноваження в масштабах підприємства; Це робить висновок Дегані (сподіваюся, її книга стане більш конкретною). По суті, Дегані заявляє про те, що, ймовірно, є неформальною практикою сьогодні, коли багато спеціальних рішень щодо управління вже приймаються на місцевому рівні.
Об’єднане обчислювальне управління
То чи варто спробувати це вдома?
Небагато тем за останній рік привернули стільки уваги у світі даних, як сітка даних. Одним із тригерів є те, що у світі, де все більше хмарне середовище, де програми та бізнес-логіка розкладаються на мікросервіси, чому б не поводитися з даними так само?
Відповідь легше сказати, ніж зробити. Наприклад, хоча монолітні системи можуть бути жорсткими та громіздкими, розподілені системи вносять свої власні складності, вітаємо чи ні. Існує ризик створення нових силосів, не кажучи вже про хаос, якщо місцеві повноваження не продумані належним чином.
Наприклад, розробка конвеєрів даних має бути частиною визначення продукту даних, але коли ці конвеєри можна повторно використовувати деінде, потрібно передбачити можливість для команд продуктів обробки даних ділитися ними IP. В іншому випадку буде багато дублюючих зусиль. Дегані закликає команди працювати в федеративному середовищі, але тут ризик наступати на чужу територію.
Розповсюдження керування життєвим циклом даних може розширити можливості, але в більшості організацій, ймовірно, буде багато випадків, коли Право власності на дані не є чітким для сценаріїв, коли кілька груп зацікавлених сторін або спільне використання, або коли дані отримані з чиїхось даних. Дегані визнає це, зазначивши, що домени зазвичай отримують дані з кількох джерел, а в У свою чергу, різні домени можуть дублювати дані (і перетворювати їх різними способами) для своїх власних споживання.
Меші даних як концепції знаходяться в стадії розробки. У своїй вступній публікації Дегані посилається на ключовий підхід до того, як зробити дані видимими: через те, що вона називає «семантикою самоопису». Але її опис короткий, вказуючи на те, що використання «добре описаного синтаксису», що супроводжується зразками наборів даних, і специфікаціями для схеми є хорошою відправною точкою для інженера обробки даних, а не для бізнесу аналітик. Ми хотіли б побачити її втілення в її майбутній книзі.
Іншу ключову вимогу щодо об’єднаного «обчислювального» управління можна промовити важко, але реалізувати її буде ще більше, як показано на діаграмі вище. Локалізація рішень якомога ближче до джерела, а глобалізація рішень щодо сумісності вимагатиме значних проб і помилок.
Усе це означає, що є вагомі причини, чому ми проводимо це обговорення. Існують розриви з даними, і багато проблем навряд чи є новими. Централізована архітектура, як-от корпоративне сховище даних, озеро даних або озерний дім, не може віддати належне в поліглотному світі. З іншого боку, можна навести аргументи на користь підходу до структури даних, який стверджує, що більш централізований підхід до керування метаданими та виявлення даних буде більш ефективним. Існує також аргумент на користь гібридного підходу, який використовує потужність уніфікованих метаданих керування структурою даних можна використовувати як логічну основу для доменів для створення та володіння своїми даними продуктів.
Іншим проблемним моментом є те, що процеси обробки даних на кожному етапі їх життєвого циклу часто розрізняються Інженери з обробки даних або розробники додатків, які створюють конвеєри, можуть бути відокремлені від лінійних організацій, які дані служить. Самообслуговування стало популярним серед бізнес-аналітиків для візуалізації та для науковців із обробки даних у розробці моделей машинного навчання та переміщенні їх у виробництво. Існує достатній аргумент, щоб розширити це до управління життєвим циклом даних для команд, які, за всією логікою, повинні володіти даними.
Але не будемо забігати наперед. Це дуже амбітна річ. Коли справа доходить до розподілу управління та власності на активи даних, як згадувалося раніше, диявол криється в деталях. І є багато деталей, які ще потрібно доопрацювати. Ми ще не переконані, що такі висхідні підходи до володіння даними поширюватимуться на всю корпоративну базу даних, і що можливо, нам слід орієнтуватися скромніше: обмежити сітку частинами організації, пов’язаними чи взаємозалежними домени.
Ми бачимо кілька постів де клієнти передчасно оголошують про перемогу. Але як цей пост штатів, лише тому, що ваша організація реалізувала об’єднаний рівень запитів або сегментувала свої озера даних, це не означає, що її розгортання стане сіткою даних. На цьому етапі впровадження сітки даних з усім її розподіленим управлінням слід розглядати як доказ концепції.
Великі дані
- Як дізнатися, чи причетні ви до витоку даних (і що робити далі)
- Боротьба з упередженнями в ШІ починається з даних
- Чесний прогноз? Як 180 метеорологів надають «досить хороші» дані про погоду
- Терапія раку залежить від запаморочливої кількості даних. Ось як це сортується в хмарі