გასული წლის განმავლობაში, რამდენიმე თემამ უფრო მეტი დისკუსია გამოიწვია მონაცემთა სამყაროში, ვიდრე მონაცემთა ბადეები. საკითხავია არის თუ არა მონაცემთა ბადეები მზად პრაიმ-ტაიმისთვის.
მონაცემთა ბადე
მონაცემთა მართვის ცენტრალიზება ან გავრცელება? ეს კითხვა დგას მას შემდეგ, რაც განყოფილების მინიკომპიუტერები შეიჭრნენ საწარმოში, რასაც კიდევ უფრო დივერსიულად მოჰყვა კომპიუტერები და LAN-ები, რომლებიც უკანა კარში გადიოდნენ. და მას შემდეგ ჩვეულებრივი სიბრძნე წინ და უკან ტრიალებს. სამუშაო ჯგუფი ან უწყებრივი სისტემები, რათა მოხდეს მონაცემების ხელმისაწვდომობა, შემდეგ საწარმოთა მონაცემთა ბაზის კონსოლიდაცია, რათა თავიდან იქნას აცილებული ყველა დუბლირება.
გახსოვთ, როდის უნდა ყოფილიყო მონაცემთა ტბა საბოლოო მდგომარეობა? ისევე, როგორც ადრე საწარმოს მონაცემთა საწყობი, მოსაზრება, რომ ყველა მონაცემი შეიძლება ერთ ადგილზე გადავიდეს ისე, რომ არსებობდა ჭეშმარიტების მხოლოდ ერთი წყარო, რომელსაც საწარმოს ყველა ფენის წვდომა შეეძლო არარეალური. ინტერნეტის კავშირი, ერთი შეხედვით იაფი შენახვა და ღრუბლის გაუთავებელი მასშტაბურობა, ჭკვიანი მოწყობილობისა და IoT მონაცემების აფეთქება საფრთხეს უქმნის მონაცემთა საწყობებს და მონაცემთა ტბებს ასე შრომატევად აწყობა.
მონაცემთა ტბის სახლები ბოლო დროს გაჩნდა ორივე სამყაროს საუკეთესო მოტანის მიზნით, ხოლო მონაცემთა ქსოვილები და მონაცემთა ინტელექტუალური ჰაბები ოპტიმიზაციას უკეთებენ ურთიერთგაგებას მონაცემთა ვირტუალიზაციასა და რეპლიკაციას შორის.უაზრო იქნება იმის თქმა, რომ ამ ალტერნატივებიდან რომელიმე გვთავაზობს საბოლოო ვერცხლის ტყვიას.
შეიყვანეთ მონაცემთა ბადე
გასული წლის განმავლობაში გაჩნდა ახალი თეორია, რომელიც აღიარებს მონაცემთა მართვის ზემოდან ქვევით ან მონოლითური მიდგომების უაზრობას: მონაცემთა ბადე. მიუხედავად იმისა, რომ ბოლო დროს ყურადღების ცენტრში იყო ხელოვნური ინტელექტი და მანქანათმცოდნეობა, მონაცემთა სამყაროში ნაკლები თემაა მეტი დისკუსიის დახატვა ვიდრე მონაცემთა ბადე. უბრალოდ გადახედეთ Google Trends-ის მონაცემებს ბოლო 90 დღის განმავლობაში: Data Mesh-ის ძიება ბევრად აღემატება მონაცემთა Lakehouse-ის ძიებას.
იგი წარმოიშვა ჟამაქ დეჰღანი, მომავალი ტექნიკური ინკუბაციის დირექტორი აზროვნების ნამუშევრები ჩრდილოეთ ამერიკა, ნამუშევრების ვრცელი ნაკრების მეშვეობით, რომელიც იწყება შესავალით ჯერ კიდევ 2019 წელს, სავარჯიშო პრინციპების და ლოგიკური არქიტექტურის შესახებ 2020 წლის ბოლოს, რომელიც მალე დასრულდება წიგნში (თუ გაინტერესებს, Starburst მონაცემები სთავაზობს შეპარული მზერა). მონაცემთა ბადეები ხშირად ყოფილა მონაცემთა ქსოვილებთან შედარებით, მაგრამ დეჰგანის ნაშრომის ყურადღებით წაკითხვა ცხადყოფს, რომ ეს უფრო პროცესს ეხება, ვიდრე ტექნოლოგიას, როგორც ჯეიმს სერამ, EY-ის არქიტექტურის ლიდერმა და ადრე Microsoft-თან ერთად, სწორად აღნიშნა. ბლოგის პოსტში. მიუხედავად ამისა, მონაცემთა ბადეების თემა (რომლებიც არის მონაცემთა ქონების განაწილებული ხედები) vs. მონაცემთა ქსოვილები (რომლებიც უფრო ცენტრალიზებულ მიდგომებს მიმართავენ) იმსახურებს საკუთარ პოსტს, როგორც ინტერესი ორივეს მიმართ საკმაოდ მსგავსი იყო.
მარტივად რომ ვთქვათ, თუ ეს შესაძლებელია, მონაცემთა ბადე არის არა ტექნოლოგიური დასტა ან ფიზიკური არქიტექტურა. მონაცემთა ბადე არის პროცესი და არქიტექტურული მიდგომა, რომელიც გადასცემს პასუხისმგებლობას მონაცემთა კონკრეტულ კომპლექტებზე დომენებზე ან სფეროებზე. ბიზნესი, რომელსაც აქვს შესაბამისი საგნობრივი ექსპერტიზა, რათა იცოდეს, რას უნდა წარმოადგენდეს ეს მონაცემები და როგორ უნდა იყოს გამოყენებული.
ამას აქვს არქიტექტურული ასპექტი: იმის ნაცვლად, რომ ვივარაუდოთ, რომ მონაცემები მონაცემთა ტბაში იქნება, თითოეული „დომენი“ იქნება პასუხისმგებელი არჩევაზე, თუ როგორ მოათავსოს და მოემსახუროს მონაცემთა ნაკრებებს, რომლებსაც ფლობს.
გარდა გარე რეგულირებისა და კორპორატიული მართვის პოლიტიკისა, დომენები არის კონკრეტული მონაცემთა ნაკრების შეგროვების მიზეზი. მაგრამ ეშმაკი დეტალებშია და ბევრი მათგანია.
ამრიგად, მონაცემთა ბადე არ არის განსაზღვრული მონაცემთა საწყობის, მონაცემთა ტბის ან მონაცემთა ტბის მიერ, სადაც მონაცემები ფიზიკურად მდებარეობს. არც ის არის განსაზღვრული მონაცემთა ფედერაციის, მონაცემთა ინტეგრაციის, შეკითხვის ძრავის ან კატალოგის ხელსაწყოებით, რომლებიც ავსებენ და ანოტირებენ ამ მონაცემთა მაღაზიებს. Რა თქმა უნდა, ამან არ შეაჩერა ტექნოლოგიების გამყიდველები საწყისი მონაცემთა ბადის რეცხვა მათი პროდუქტები. მომდევნო წლის განმავლობაში, ჩვენ სავარაუდოდ დავინახავთ კატალოგების, მოთხოვნის ძრავების, მონაცემთა მილსადენების და მმართველობის მომწოდებლებს, რომლებიც თავიანთ ინსტრუმენტებსა თუ პლატფორმებს მონაცემთა ბადის შუქზე ხატავენ. მაგრამ როდესაც ხედავთ მარკეტინგულ შეტყობინებებს, გახსოვდეთ, რომ მონაცემთა ბადეები ეხება პროცესს და როგორ ახორციელებთ ტექნოლოგიას. მაგალითად, ფედერაციული შეკითხვის ძრავა უბრალოდ გამაძლიერებელია, რომელსაც შეუძლია დაეხმაროს გუნდს იმპლემენტაციაში, მაგრამ დამოუკიდებლად არ აქცევს მონაცემთა საკუთრებას მონაცემთა ბადედ.
ძირითადი საყრდენები
მონაცემთა ბადე რთული კონცეფციაა, მაგრამ დასაწყებად საუკეთესო გზაა მის უკან არსებული პრინციპების გაგება.
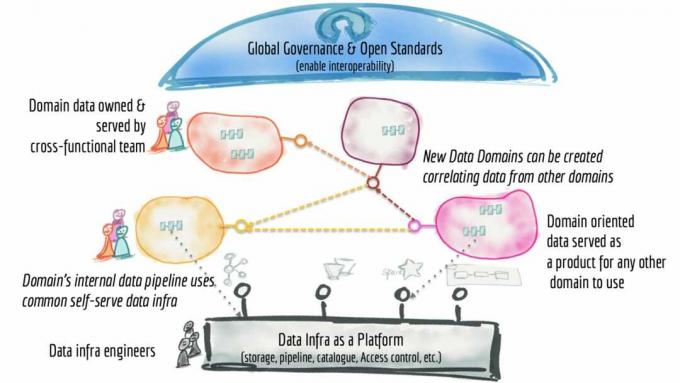
პირველი პრინციპი არის დაახლოებით მონაცემთა საკუთრება - ის უნდა იყოს ადგილობრივი, დასახლებული გუნდთან, რომელიც პასუხისმგებელია მონაცემთა შეგროვებაზე ან/და მოხმარებაზე. თუ არსებობს მონაცემთა ბადეების ცენტრალური პრინციპი, ეს არის ის - ეს არის ის, რომ მონაცემთა კონტროლი უნდა გადაეცეს იმ დომენს, რომელიც ფლობს მას. იფიქრეთ დომენზე, როგორც დომენის ცოდნის გაფართოებაზე – ეს არის ორგანიზაციული ერთეული ან ადამიანების ჯგუფი, რომლებსაც ესმით რა არის მონაცემები და როგორ უკავშირდება ის ბიზნესს. ეს არის ერთეული, რომელმაც იცის, რატომ გროვდება მონაცემთა ნაკრები; როგორ მოიხმარს და ვის მიერ; და როგორ უნდა იმართებოდეს მისი სასიცოცხლო ციკლი.
საქმეები ცოტა უფრო რთული ხდება იმ მონაცემებისთვის, რომლებიც გაზიარებულია დომენებში, ან სადაც მონაცემები ერთი დომენის ქვეშ არის დამოკიდებული სხვა დომენების მონაცემებზე ან API-ებზე. კეთილი იყოს თქვენი მობრძანება რეალურ სამყაროში, სადაც მონაცემები იშვიათად არის კუნძული. ეს არის ერთ-ერთი ადგილი, სადაც ბადეები შეიძლება წებოვანი გახდეს.
მეორე პრინციპი არის ის, რომ მონაცემები უნდა განიხილებოდეს როგორც ა პროდუქტი. ეს არის, ფაქტობრივად, უფრო ვრცელი ხედვა იმის შესახებ, თუ რას მოიცავს მონაცემთა ერთეული, რადგან ის უფრო მეტია, ვიდრე ნაწილი მონაცემები ან კონკრეტული მონაცემთა ნაკრები და იღებს უფრო მეტად სასიცოცხლო ციკლის ხედვას იმის შესახებ, თუ როგორ შეიძლება და როგორ უნდა იყოს მონაცემთა სერვისი და მოხმარებული. და პროდუქტის განმარტების ნაწილი არის მომსახურების დონის ფორმალური მიზანი, რომელიც შეიძლება ეხებოდეს ფაქტორებს როგორიცაა შესრულება, სანდოობა და სანდოობა, მონაცემთა ხარისხი, უსაფრთხოებასთან დაკავშირებული ავტორიზაციის წესები და ა.შ on. ეს არის დაპირება, რომელსაც დომენი, რომელიც ფლობს მონაცემებს, აძლევს ორგანიზაციას.
კონკრეტულად, მონაცემთა პროდუქტი სცილდება მონაცემთა ნაკრების ან მონაცემთა ერთეულს და მოიცავს მონაცემთა მილსადენების კოდს, რომელიც აუცილებელია მონაცემთა გენერირებისთვის და/ან გარდაქმნისთვის; ასოცირებული მეტამონაცემები (რომელიც, რა თქმა უნდა, შეიძლება მოიცავდეს ყველაფერს სქემის განსაზღვრებიდან შესაბამის ბიზნესამდე ტერმინების ტერმინები, მოხმარების მოდელები ან ფორმები, როგორიცაა მიმართებითი ცხრილები, მოვლენები, ჯგუფური ფაილები, ფორმები, გრაფიკები, და ა.შ.); და ინფრასტრუქტურა (როგორ და სად ინახება და მუშავდება მონაცემები). ამას აქვს მნიშვნელოვანი ორგანიზაციული შედეგები, იმის გათვალისწინებით, რომ მონაცემთა მილსადენების მშენებლობა ხშირად ა ცალკეული საქმიანობა, რომელსაც დამოუკიდებლად ამუშავებენ სპეციალისტები, როგორიცაა მონაცემთა ინჟინრები და დეველოპერები. ყოველ შემთხვევაში, მატრიცის კონტექსტში, ისინი უნდა იყვნენ იმ დომენის ან ბიზნეს გუნდის ნაწილი ან ასოცირებული, რომელიც ფლობს მონაცემებს.
და სხვათა შორის, ეს მონაცემთა პროდუქტი უნდა აკმაყოფილებდეს რამდენიმე ძირითად მოთხოვნას. მონაცემები მზად უნდა იყოს აღმოჩენილი; სავარაუდოდ, ეს არის ის, რისთვისაც არის კატალოგები. ასევე უნდა იყოს შესასწავლი, საშუალებას აძლევს მომხმარებლებს გაბურღონ. და ეს უნდა იყოს მისამართიანი; აქ დეჰგანი აღნიშნავს, რომ მონაცემებს უნდა ჰქონდეთ უნიკალური კანონიკური მისამართები, რაც უფრო მაღალი დონის აბსტრაქციად ჟღერს, რომ სემანტიკური ვებ ნარჩენი, კლასიკური ური. საბოლოოდ, მონაცემები უნდა იყოს გასაგები (დეჰგანი გვთავაზობს „თვითაღწერის სემანტიკასა და სინტაქსს“); სანდო; და უსაფრთხო. არ უნდა დაგვავიწყდეს, რომ რადგან ეს გამიზნულია მრავალი დომენის გადაკვეთაზე, საჭირო იქნება მონაცემთა ჰარმონიზაციის ძალისხმევა.
მიუხედავად იმისა, რომ მონაცემთა ბადე არ არის განსაზღვრული ტექნოლოგიით, რეალურ სამყაროში, კონკრეტული საინჟინრო ჯგუფები ფლობენ მონაცემთა ბაზას, იქნება ეს მონაცემთა ბაზა, მონაცემთა ტბა და/ან ნაკადის ძრავა. ეს ეხება მიუხედავად იმისა, ახორციელებს თუ არა ორგანიზაცია ამ პლატფორმებს შენობაში, თუ სარგებლობს მართული მონაცემთა ბაზის სერვისით ღრუბელში, და უფრო სავარაუდოა, ორივე ადგილას. ვიღაცას უნდა ჰქონდეს ძირითადი პლატფორმა და ეს პლატფორმები ასევე ჩაითვლება პროდუქტებად, საგნების გრანდიოზულ სქემაში.
თვითმომსახურების მონაცემთა პლატფორმა
მესამე პრინციპი არის მონაცემების ხელმისაწვდომობის აუცილებლობა თვითმომსახურების მონაცემთა პლატფორმა როგორც ზემოთ არის ნაჩვენები. რა თქმა უნდა, თვითმომსახურება გახდა მონაცემთა უფრო ფართო წვდომის სიტყვა, რადგან ეს არის მონაცემების მიღების ერთადერთი გზა მოხმარებადი, რადგან მონაცემთა მოცულობა ფართოვდება, იმის გათვალისწინებით, რომ IT რესურსები სასრულია, განსაკუთრებით მონაცემთა ინჟინრებთან, რომლებიც იშვიათია და ძვირფასი. ის, რასაც იგი აქ აღწერს, არ უნდა აგვერიოს თვითმომსახურების პლატფორმებთან მონაცემთა ვიზუალიზაციისთვის ან მონაცემთა მეცნიერებისთვის; ეს უფრო მეტად ინფრასტრუქტურისა და პროდუქტის შემქმნელებისთვისაა.
ამ პლატფორმას შეიძლება ჰქონდეს, როგორც დეჰგანი ამბობს, სხვადასხვა თვითმფრინავები (ან სკინები), რომლებიც ემსახურებიან პრაქტიკოსთა სხვადასხვა ნაწილს. მაგალითები შეიძლება მოიცავდეს ინფრასტრუქტურის უზრუნველყოფის თვითმფრინავს, რომელიც ეხება მონაცემთა მარშალიზაციის ყველა მახინჯ ფიზიკურ მექანიკას (როგორიცაა შენახვის უზრუნველყოფა; წვდომის კონტროლის დაყენება; და შეკითხვის ძრავა); პროდუქტის განვითარების გამოცდილება, რომელიც უზრუნველყოფს დეკლარაციულ ინტერფეისს მონაცემთა სასიცოცხლო ციკლის მართვისთვის; და ზედამხედველობის თვითმფრინავი, რომელიც მართავს მონაცემთა პროდუქტებს. დეჰგანი ბევრად უფრო ამომწურავია იმის შესახებ, თუ რას უნდა დაუჭიროს მხარი თვითმომსახურების მონაცემთა პლატფორმამ და აქ არის სია.
და ბოლოს, არც ერთი მიდგომა მონაცემთა მართვისადმი არ არის სრულყოფილი მმართველობის გარეშე. ეს არის მეოთხე პრინციპი და ამას დეჰგანი უწოდებს ფედერაციული გამოთვლითი მმართველობა. ეს ადასტურებს რეალობას, რომ განაწილებულ გარემოში იქნება მრავალი, ურთიერთდამოკიდებული მონაცემთა პროდუქტი, რომელიც უნდა ურთიერთთანამშრომლობდეს და ამით მხარი დაუჭიროს მონაცემთა სუვერენიტეტის მანდატებს და მონაცემთა შენახვის თანმხლებ წესებს და წვდომა. საჭირო იქნება მონაცემთა ხაზის სრულად გაგება და თვალყურის დევნება.
ერთი პოსტი არ გაამართლებს ამ თემას. იდეის გაფუჭების რისკის ქვეშ, ეს ნიშნავს, რომ მონაცემთა პროდუქტებისა და მონაცემების ფედერაციაა პლატფორმის პროდუქტის მფლობელები ქმნიან და აღასრულებენ წესების გლობალურ კომპლექტს, რომელიც ვრცელდება მონაცემთა ყველა პროდუქტზე და ინტერფეისები. რაც აკლია აქ არის ის, რომ უნდა იყოს უზრუნველყოფილი უმაღლესი მენეჯმენტისთვის, როდესაც საქმე ეხება საწარმოს პოლიტიკასა და მანდატებს; დეჰგანი ამას ასკვნის (იმედია მისი წიგნი უფრო კონკრეტული გახდება). არსებითად, დეჰგანი აცხადებს იმას, რაც, სავარაუდოდ, დღეს არაფორმალური პრაქტიკაა, სადაც მმართველობის შესახებ ბევრი გადაწყვეტილების მიღება უკვე მიიღება ადგილობრივ დონეზე.
ფედერალური გამოთვლითი მმართველობა
ასე რომ, უნდა სცადოთ ეს სახლში?
რამდენიმე თემამ მიიპყრო იმდენი ყურადღება მონაცემთა სამყაროში გასული წლის განმავლობაში, როგორც მონაცემთა ბადე. ერთ-ერთი გამომწვევი ის არის, რომ მზარდ ღრუბლოვან სამყაროში, სადაც აპლიკაციები და ბიზნეს ლოგიკა იშლება მიკროსერვისებად, რატომ არ უნდა მოექცეთ მონაცემებს იმავე გზით?
პასუხის თქმა უფრო ადვილია, ვიდრე გაკეთება. მაგალითად, მაშინ, როცა მონოლითური სისტემები შეიძლება იყოს ხისტი და მოუხერხებელი, განაწილებული სისტემები წარმოადგენენ საკუთარ სირთულეებს, მოგესალმებით თუ არა. არსებობს ახალი სილოსების შექმნის რისკი, რომ აღარაფერი ვთქვათ ქაოსზე, როდესაც ადგილობრივი გაძლიერება სათანადოდ არ არის გააზრებული.
მაგალითად, მონაცემთა მილსადენების განვითარება უნდა იყოს მონაცემთა პროდუქტის განმარტების ნაწილი, მაგრამ როდესაც ამ მილსადენების ხელახლა გამოყენება შესაძლებელია სხვაგან, უნდა იყოს უზრუნველყოფილი მონაცემთა პროდუქტის გუნდების გაზიარებისთვის IP. წინააღმდეგ შემთხვევაში, ბევრი გაორმაგებული ძალისხმევაა. დეჰგანი გუნდებს ფედერაციულ გარემოში მუშაობისკენ მოუწოდებს, მაგრამ აქ რისკი სხვის მოედანზე დგას.
მონაცემთა სასიცოცხლო ციკლის მენეჯმენტის განაწილება შეიძლება იყოს ძალაუფლების მომტანი, მაგრამ ორგანიზაციების უმეტესობაში, სავარაუდოდ, იქნება უამრავი შემთხვევა, როდესაც მონაცემთა საკუთრება არ არის მკაფიო სცენარებისთვის, სადაც რამდენიმე დაინტერესებული მხარე ან იზიარებს გამოყენებას ან სადაც მონაცემები მიღებულია სხვისი მონაცემები. დეჰგანი აღიარებს ამას და აღნიშნავს, რომ დომენები, როგორც წესი, იღებენ მონაცემებს მრავალი წყაროდან და თავის მხრივ, სხვადასხვა დომენმა შეიძლება გააორმაგოს მონაცემები (და გარდაქმნას ისინი სხვადასხვა გზით) საკუთარი თავისთვის მოხმარება.
მონაცემთა ბადეები, როგორც კონცეფციები, სამუშაოები მიმდინარეობს. თავის შესავალ პოსტში, დეჰგანი მიუთითებს მონაცემთა აღმოჩენის გასაკეთებლად ძირითად მიდგომაზე: „თვითაღწერის სემანტიკის“ მეშვეობით. მაგრამ მისი აღწერა მოკლეა, მიუთითებს, რომ "კარგად აღწერილი სინტაქსის" გამოყენება, რომელსაც თან ახლავს მონაცემთა ნაკრების ნიმუში და სქემის სპეციფიკაციები, კარგი საწყისი წერტილია -- მონაცემთა ინჟინრისთვის და არა ბიზნესისთვის ანალიტიკოსი. ეს ის წერტილია, რომ ჩვენ გვინდა ვიხილოთ მისი ხორცი მის მომავალ წიგნში.
კიდევ ერთი საკვანძო მოთხოვნა, ფედერაციული „გამოთვლითი“ მმართველობისთვის, შეიძლება გამოთქმა იყოს პირის ღრუში, მაგრამ მისი განხორციელება კიდევ უფრო მეტი იქნება, როგორც ზემოთ მოცემულ დიაგრამაზე ჩანს. გადაწყვეტილებების ლოკალიზაცია წყაროსთან ახლოს, ხოლო გლობალიზაციის გადაწყვეტილებები თავსებადობასთან დაკავშირებით მოითხოვს მნიშვნელოვან ცდას და შეცდომას.
ყველაფერი, რაც ნათქვამია, არსებობს კარგი მიზეზები, რის გამოც ჩვენ ამ დისკუსიას ვაწარმოებთ. არსებობს მონაცემების გათიშვა და ბევრი საკითხი ახალი არ არის. ცენტრალიზებული არქიტექტურა, როგორიცაა საწარმოს მონაცემთა საწყობი, მონაცემთა ტბა ან მონაცემთა ტბა, ვერ ამართლებს პოლიგლოტ სამყაროში. მეორეს მხრივ, არგუმენტების მოყვანა შესაძლებელია მონაცემთა ქსოვილის მიდგომისთვის, რომელიც ამტკიცებს, რომ მეტამონაცემების მართვისა და მონაცემთა აღმოჩენის უფრო ცენტრალიზებული მიდგომა უფრო ეფექტური იქნება. ასევე დასაშვებია ჰიბრიდული მიდგომა, რომელიც იყენებს ერთიანი მეტამონაცემების ძალას მონაცემთა ქსოვილის მენეჯმენტი შეიძლება გამოყენებულ იქნას, როგორც ლოგიკური საყრდენი დომენებისთვის, რათა შექმნან და ფლობდნენ მათ მონაცემებს პროდუქტები.
კიდევ ერთი მტკივნეული წერტილი არის ის, რომ მონაცემთა დამუშავების პროცესები მისი სასიცოცხლო ციკლის თითოეულ ეტაპზე ხშირად არაერთგვაროვანია მონაცემთა ინჟინრები ან აპლიკაციების დეველოპერები, რომლებიც აშენებენ მილსადენებს, შეიძლება განქორწინდნენ იმ ხაზის ორგანიზაციებისგან, რომლებსაც მონაცემები აქვთ ემსახურება. თვითმომსახურება პოპულარული გახდა ბიზნეს ანალიტიკოსებთან ვიზუალიზაციისთვის და მონაცემთა მეცნიერებისთვის ML მოდელების შემუშავებაში და მათ წარმოებაში გადატანაში. არსებობს კარგი შემთხვევა, რომ ეს გავაფართოვოთ მონაცემთა სასიცოცხლო ციკლის მართვაში იმ გუნდებისთვის, რომლებიც, ყველა ლოგიკით, უნდა ფლობდნენ მონაცემებს.
მაგრამ ნუ გავუსწრებთ თავს. ეს არის ძალიან ამბიციური რამ. რაც შეეხება მონაცემთა აქტივების მართვისა და საკუთრების განაწილებას, როგორც უკვე აღვნიშნეთ, ეშმაკი დეტალებშია. და არის უამრავი დეტალი, რომელიც ჯერ კიდევ გასასწორებელია. ჩვენ ჯერ არ გვაქვს გაყიდული, რომ მონაცემთა ფლობის ასეთი ქვემოდან ზევით მიდგომები გავრცელდება მთელ საწარმოს მონაცემთა საკუთრებაში და შესაძლოა, უფრო მოკრძალებულად მივმართოთ ჩვენს სამიზნეებს: შევზღუდოთ ქსელი ორგანიზაციის ნაწილებით, რომლებიც დაკავშირებულია ან ურთიერთდამოკიდებულებით. დომენები.
ჩვენ ვხედავთ რამდენიმე პოსტი სადაც კლიენტები ნაადრევად აცხადებენ გამარჯვებას. მაგრამ როგორც ეს პოსტი მხოლოდ იმიტომ, რომ თქვენმა ორგანიზაციამ დანერგა ფედერირებული შეკითხვის ფენა ან მისი მონაცემთა ტბების სეგმენტი, არ აქცევს მის განთავსებას მონაცემთა ბადეს. ამ ეტაპზე მონაცემთა ბადის დანერგვა მთელი მისი განაწილებული მმართველობით უნდა განიხილებოდეს, როგორც კონცეფციის მტკიცებულება.
Დიდი მონაცემები
- როგორ გავარკვიოთ, ხართ თუ არა ჩართული მონაცემების დარღვევაში (და რა უნდა გააკეთოთ შემდეგ)
- AI-ში მიკერძოების წინააღმდეგ ბრძოლა იწყება მონაცემებით
- სამართლიანი პროგნოზი? როგორ აწვდიან 180 მეტეოროლოგი ამინდის „საკმარისად კარგ“ მონაცემებს
- კიბოს თერაპია დამოკიდებულია თავბრუდამხვევ მონაცემებზე. აი, როგორ არის დალაგებული ღრუბელში